

Generatieve AI verandert fundamenteel hoe we informatie opzoeken. Waar we vroeger de links volgden die Google ons aanreikte, krijgen we nu steeds vaker een kant-en-klaar antwoord. Dit vraagt om nieuwe strategieën voor online zichtbaarheid, bovenop bestaande SEO. In dit artikel duiken we dieper in hoe deze AI-zoekmachines werken.
Verschillende platforms bieden AI-zoekmachines aan, waarvan ChatGPT van OpenAI de populairste is. Google toont sinds kort automatisch een AI-overview bij zoekvragen. Met AI Mode integreert Google generatieve AI nog sterker in de zoekfunctie. Andere opties zijn Perplexity en Bing Copilot.
Voor wie online zichtbaar wil zijn, is het essentieel om te begrijpen hoe deze AI-zoekmachines werken. De onderliggende technologie evolueert naar een hybride vorm waarin traditionele en semantische methodes samenkomen. Strategieën voor online zichtbaarheid moeten daarom op beide aspecten inspelen.
Ontwikkeling taalmodel
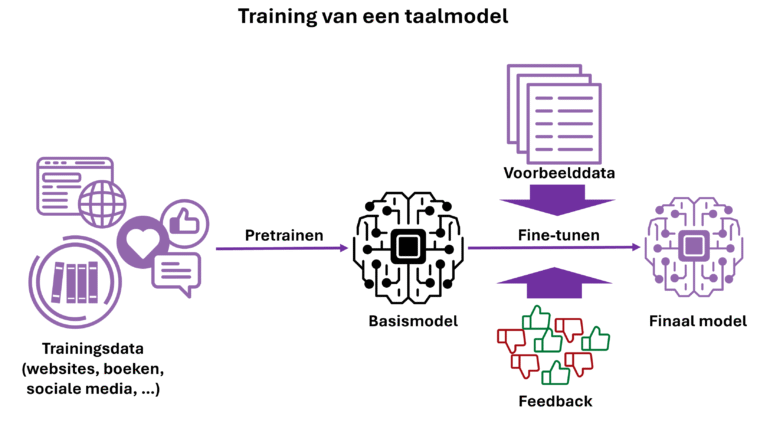
De basis van dit nieuwe zoekparadigma is een AI-taalmodel of LLM (Large Language Model). Deze modellen begrijpen natuurlijke taal en drijven chatbots, zoals ChatGPT, aan. Ze halen hun kennis uit data via machine learning. Dit trainingsproces verloopt in verschillende stappen.
Stap 1: pretraining
De eerste stap is pretraining, waarbij het model enorme hoeveelheden tekst verwerkt, de trainingsdata. Deze komt uit verschillende bronnen zoals websites, boeken en social media. Je kunt je voorstellen dat het model bijna alles heeft verwerkt wat op het internet te vinden is tot op het moment waarop de trainingsdata werd verzameld. Dit tijdstip heet de kennis-cutoff van het model. Het bevat geen informatie over gebeurtenissen na deze datum.
Stap 2: het genereren van tekst
Het model genereert tekst woord voor woord op basis van de voorgaande woorden. Tijdens het trainen leert het de trainingsdata zo goed mogelijk te benaderen. In het algemeen geldt: hoe groter het model en hoe meer data het verwerkt, hoe beter de prestaties. Het taalbegrip dat LLM’s zo ontwikkelen is indrukwekkend.
Stap 3: het basismodel ontstaat
Na het pretrainen ontstaat het basismodel. Dit vult teksten goed aan, maar is nog niet erg nuttig. Het kan bijvoorbeeld niet converseren met gebruikers. Deze mogelijkheid wordt toegevoegd in de volgende fase: fine-tuning.
Stap 4: finetuning
Er zijn verschillende methodes voor finetuning, maar deze gebeurt meestal op basis van goede voorbeelden van gewenst gedrag van het model en feedback op de antwoorden. Zo leert het model taken uit te voeren, zoals converseren met gebruikers. Het leert ook ‘gewenst’ gedrag te vertonen zoals het niet promoten van illegaal gedrag en toxisch taalgebruik niet te hanteren.
Extra informatie toevoegen (RAG)
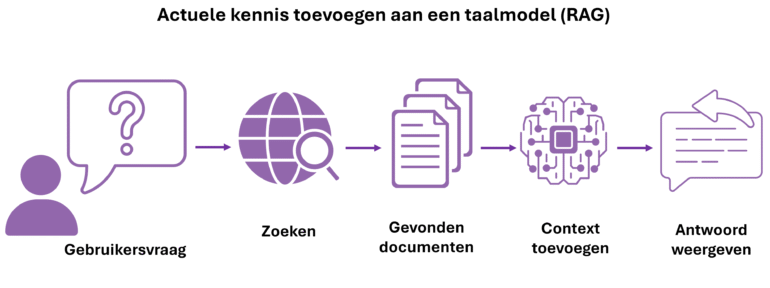
Op dit punt kan het model een gebruikersvraag beantwoorden op basis van de trainingsdata. Als de nodige informatie ontbreekt of onvolledig is, bijvoorbeeld bij een vraag over een gebeurtenis na de kennis-cutoff, zal het model deze zelf proberen in te vullen. Dit staat bekend als hallucineren. Dit kan verholpen worden door het model te voorzien van extra relevante context bij het beantwoorden van de vraag.
Extra relevante informatie wordt toegevoegd via RAG of Retrieval Augmented Generation. Retrieval staat voor het ophalen van relevante informatie, Augmented voor het toevoegen van deze context aan het model, en Generation voor het genereren van het finale antwoord.
Er zijn verschillende methodes om informatie op te halen (Retrieval). Traditioneel gebeurt dit op basis van kernwoorden, maar tegenwoordig wordt steeds vaker semantisch zoeken gebruikt. Bij deze methode zet een AI-model tekst om naar een vector of embedding die de betekenis vastlegt. De afstand tussen vectoren geeft aan hoe gelijkaardig de bijhorende teksten zijn. Zo kunnen tekstfragmenten vergeleken worden op betekenis in plaats van op exacte woordkeuze. Gerelateerde concepten worden herkend, zelfs als ze andere woorden gebruiken.
Door de vector van de zoekvraag te vergelijken met de vectoren van beschikbare teksten worden de meest relevante documenten geselecteerd. Deze worden als extra context aan het taalmodel toegevoegd om de vraag te beantwoorden. In de praktijk wordt meestal gebruikgemaakt van hybride zoekmethodes die zowel semantisch als op basis van kernwoorden zoeken naar relevante teksten.
Zo wordt relevante context geselecteerd uit beschikbare bronnen zoals actuele webpagina’s. Deze context wordt aan het taalmodel toegevoegd, dat vervolgens een antwoord formuleert.
Aanvullende technieken
Dit is de algemene opzet voor AI-zoekmachines, maar elk platform heeft zijn eigen concrete uitwerking en vaak nog extra stappen om betere antwoorden te genereren. We bekijken hier een aantal van deze extra technieken.
- Meestal wordt er eerst een taalmodel gebruikt om de gebruikersvraag te interpreteren en te verfijnen. Bij Google worden er op basis van deze interpretatie nog een aantal bijvragen geformuleerd die ook gebruikt worden om relevante context te zoeken, een proces dan men query fan-out noemt.
- Om het doel van de gebruiker beter te begrijpen, wordt extra context toegevoegd zoals: de locatie, het tijdstip, eerdere vragen van de gebruiker en andere persoonlijke informatie. Hierdoor kan dezelfde vraag op verschillende momenten, plaatsen of voor verschillende gebruikers leiden tot een ander antwoord.
- Klassieke zoekmachines verzamelen de documenten. OpenAI en Perplexity hebben geen eigen web-index en gebruiken daarom Bing en Google om in realtime relevante websites op te halen. Documenten worden opgesplitst in kleine tekstfragmenten om de hoeveelheid context te beperken. Elk fragment krijgt een eigen embedding.
- Ten slotte worden enkele bronteksten geselecteerd en als klikbare citaties toegevoegd. Deze citaties worden niet bepaald op basis van waar de informatie vandaan komt, maar op basis van semantische gelijkenis met het finale antwoord. Perplexity vormt hierop een uitzondering: dit platform bepaalt eerst de relevante referenties en gebruikt deze vervolgens als extra context, waardoor het proces transparanter verloopt.
Lessen voor online zichtbaarheid
Traditionele zoekmethodes blijven onderdeel van de nieuwe aanpak, waardoor klassieke SEO relevant blijft. Daarnaast is het belangrijk om rekening te houden met hoe de content semantische overeen komt met mogelijke zoekvragen.
Een belangrijk verschil met traditionele SEO op basis van kernwoorden is dat content nu wordt geselecteerd op semantische overeenstemming. De informatie moet daarom duidelijk zijn in zijn geheel, niet enkel op het niveau van kernwoorden. Omdat er wordt gewerkt met aparte tekstfragmenten, loont het om elk deel zoveel mogelijk begrijpelijk te houden, ook wanneer de rest van de tekst wegvalt. Structureer pagina’s zodat kernbeweringen bestaan als uitlichtbare passages.
AI-zoekmachines zijn een fundamentele verandering in hoe informatie wordt gevonden. Voor contentmakers betekent dit een hybride aanpak met technische optimalisatie én semantische helderheid. De focus verschuift van ranken naar content die AI-modellen correct kunnen interpreteren. Gestructureerde, contextrijke en semantisch heldere content heeft de beste kansen op zichtbaarheid.



